
This article explains the rationale behind the creation of TurtleQueue. Jump to Turtlequeue if you are already familiar with message queues such as RabbitMQ or Apache Pulsar.
Communications first: HTTP, Message queues
In the information age, we are witnessing an explosion in the number of programs everywhere. Small apps, big software powering entire industries. Even for small applications, it is now extremely common to be broken up into several parts working together. Therefore these little subprograms need to exchange data, messages, commands, and updates between them. How they communicate is, therefore, an important architectural decision.
One early solution, still very much in use today is to use HTTP. This is an easy approach, however, it has some drawbacks. Consider for example the following scenarios:
- A program needs an update, resulting in downtime. Are messages processed or are they lost?
- An increase in messages puts pressure on the server. Are messages processed or are they lost?
- A new requirement means that messages have to be processed differently. After deploying a new version, can previous messages be re-processed?
Another solution is to use message queues. They solve all of the above problems by placing themselves between the participants in the discussion. Consider the above scenarios, but this time a message queue is used for communications:
- A program needs an update, resulting in downtime. Messages are saved until the recipient is ready.
- An increase in messages puts pressure on the server. The queue will absorb the load. If needed backpressure will be propagated.
- A new requirement means that messages have to be processed differently. After deploying a new version, historical messages can be replayed.
 A simple queue
A simple queue
From an architectural point of view Message queues decouple the what from the when, and reduce the knowledge needed for an application to work. This gives us increased reliability and observability.
Both approaches are very popular, perhaps HTTP even more so than message queues. As a software developer, I have encountered time and time again situations where HTTP requests are used where message queues would be a better choice.
Why? It is my opinion that the slightly higher initial cost makes them less appealing to the impatient developer. And the message queues providing the most benefits (such as keeping a history of messages), are also harder to set up. TurtleQueue aims to lower the barrier to entry for message queues, and therefore make the technically superior solution also the easiest to get started with.
State of the art: the Log
There many differences between message queue systems. They are not covered here1.
But recently message queues have had one major evolution, that was popularized by Apache Kafka: the Log 3. By internally representing the messages as an append-only log, Kafka pioneered a way to store messages efficiently, reliably and did open up new possibilities for application developers.
Producers still push messages onto a named queue, and consumers read from it. Additionally, consumers can now decide which part they want to read. They can start from the incoming messages, or the start of the topic. They can split messages from a named queue between them, or every consumer can get all messages from the queue.
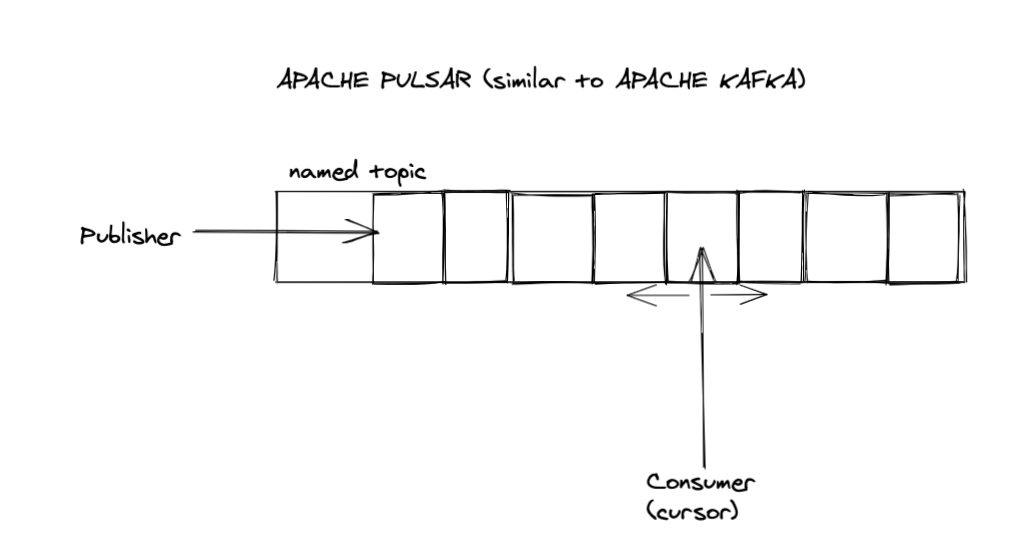 topic built on top of an append-only log
topic built on top of an append-only log
Apache Pulsar (upon which TurtleQueue is built) builds on top of the same foundation and improves on it. It exposes a cursor that advances to consume the next message. The cursor's position can be changed to something else, like the beginning of the queue.
New architectures have emerged and are still being improved upon that benefit from these developments, like the lambda architecture.
TurtleQueue
I have been using a variety of messaging systems over the years. Chronologically, I have been using AMQP/Rabbit/Kafka and switched to Apache Pulsar since 20172. These messaging systems are great, each generation improving over the previous and are an essential part of many powerful and reliable systems.
Unfortunately, they are sometimes ignored by programmers under tight time constraints, and such important architectural decisions can have long-lasting consequences.
TurtleQueue aims to make it really easy and cheap to use message queues. With TurtleQueue, a programmer can send and receive messages in no more time than it takes to set up a web server.
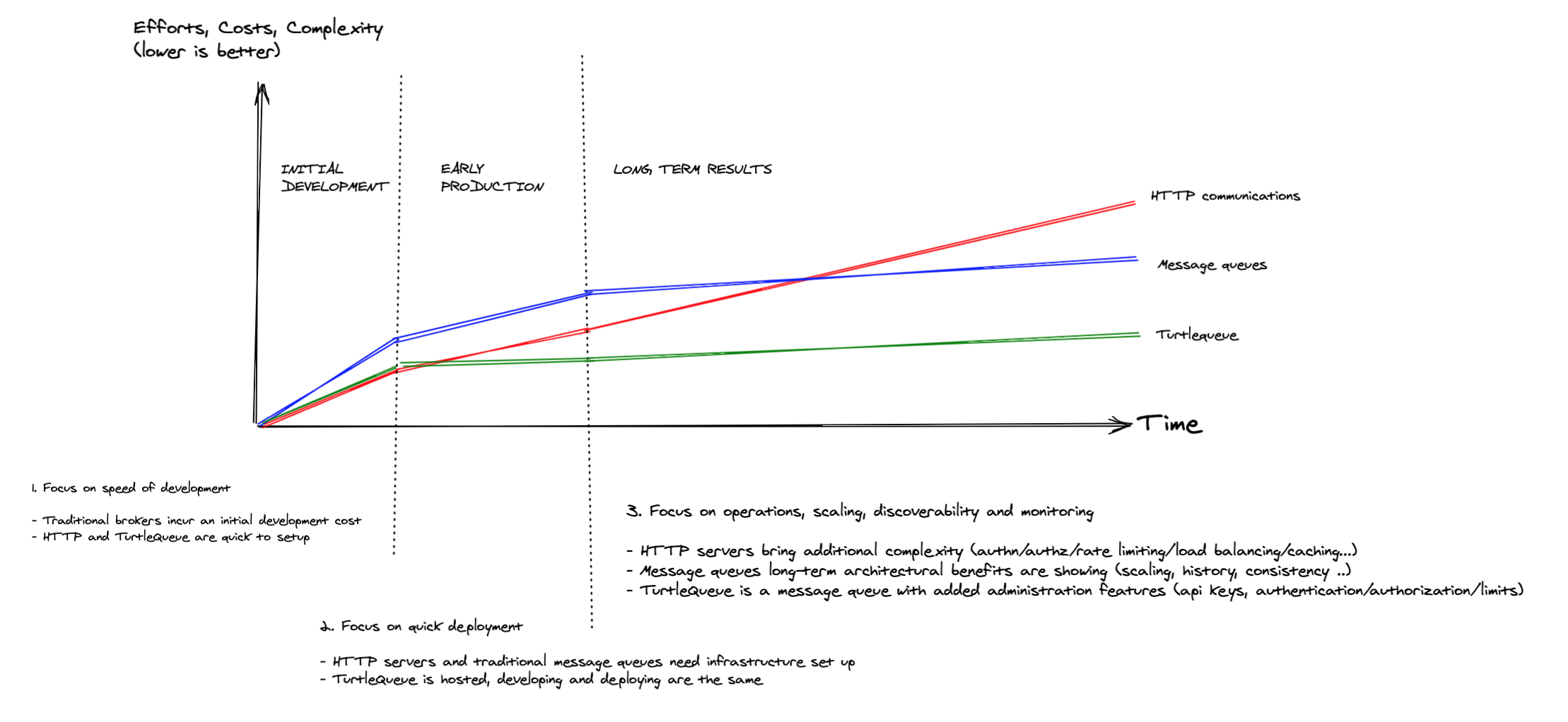 unscientific graph showing costs over time of different solutions. Of course, Turtlequeue wins!
unscientific graph showing costs over time of different solutions. Of course, Turtlequeue wins!
How?
TurtleQueue is built on top of Apache Pulsar:
- great performance
- well-understood data model
- useful features
TurtleQueue adds the benefits of a SaaS service:
- no infrastructure to maintain
- built-in authentication and authorization designed for internal and external use
- additional features like jsonPath filtering
Behind the scenes
The main goals of TurtleQueue are (a) ease of use and (b) being cheap. How do I go about it?
Tq (turtlequeue) users do not have to care about how the cluster operates (typical SaaS). This is achieved through a custom Pulsar proxy. This proxy also collects metrics that can be exposed to the user, and operations that would require using the SDK or the administration CLI can be done there as well.
Behind the scenes, there is only one Pulsar cluster4. This lowers the costs of hosting dramatically. Even the smallest production pulsar cluster requires:
- ZooKeeper node(s)
- Bookies nodes
- Brokers node(s)
- (optional) Function workers node(s)
- (optional) Proxies node(s)
- Pulsar Manager
- Prometheus
- Grafana
- typically on top of Kubernetes
Hosting small setups is costly. By having a shared cluster I can lower the costs enough to provide a free "try me" service at little to no cost to me. And nobody will suffer from the "noisy neighbour" as Pulsar is designed to be multi-tenant and can enforce limits per tenant.
Give it a try! It is free and non-binding: https://turtlequeue.com/docs/
- The curious reader could look for these: message queue or publish-subscribe model, smart broker or smart clients, persistent or ephemeral storage, retention limits, distributed or not, streaming vs batching, append-only log. Zach Tellman's talk "Everything Will Flow". Anything Martin Kleppmann writes.↩
- https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying↩
- Possibly earlier than 2017 though I cannot remember the exact date. I only answering about it on StackOverflow this far back: https://stackoverflow.com/a/47477765↩
- One logical cluster from the end-user point of view. There are variations of this as described here: https://streamnative.io/en/blog/tech/2021-03-02-taking-an-in-depth-look-at-how-to-achieve-isolation-in-pulsar but these are transparent to the final user↩